SQL Server catalogs #
You can use a SQL Server catalog to configure access to a SQL Server or compatible database in the following deployments:
Amazon RDS on Amazon Web Services:
Azure SQL Database on Microsoft Azure:
SQL Server on Google Cloud:
Follow these steps to create a catalog for SQL Server:
- In the navigation menu, select Data, then Catalogs.
- Click Create catalog.
- On the Create a catalog pane, click the SQL Server icon.

- Configure the catalog as prompted in the dialog.
- Test the connection.
- Connect the catalog.
- Set any required permissions.
- Add the new catalog to a cluster.
The following sections provide more detail for creating SQL Server catalog connections.
Select a cloud provider #
The Cloud provider configuration is necessary to allow Starburst Galaxy to correctly match catalogs and clusters.
The data source configured in a catalog, and the cluster must operate in the same cloud provider and region for performance and cost reasons.

Define catalog name and description #
The Catalog name is visible in the query editor and other clients. It is used to identify the catalog when writing SQL or showing the catalog and its nested schemas and tables in client applications.
The name is displayed in the query editor, and in the output of a SHOW
CATALOGS command.
It is used to fully qualify the name of any table in SQL queries following the
catalogname.schemaname.tablename syntax. For example, you can run the
following query in the sample cluster without first setting the catalog or
schema context: SELECT * FROM tpch.sf1.nation;.
The Description is a short, optional paragraph that provides further details about the catalog. It appears in the Starburst Galaxy user interface and can help other users determine what data can be accessed with the catalog.

Multiple connections #
The SQL Server catalog can only access a single SQL Server database within a single catalog. If you have multiple SQL Server databases, or want to connect to multiple SQL Server instances, you must configure additional instances of the SQL Server catalog.
Configure the connection #
Read further to learn about each supported connection method. The following sections detail the setup for the supported cloud providers.
-
Connect directly
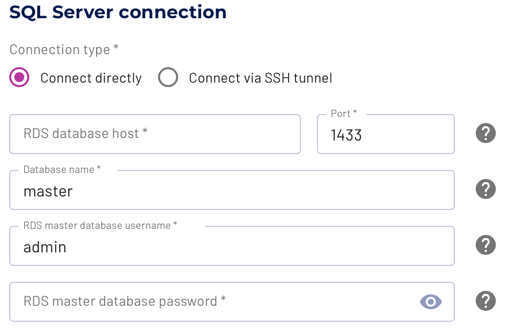
The connection to the database requires a username, password authentication, and the details necessary to connect to the database server, typically hostname or IP address and port. -
Connect via SSH tunnel
A connection to the database can be established directly, if the Starburst Galaxy IP range/CIDR is allowed to connect.If the database is only accessible inside the virtual private cloud (VPC) of the cloud provider, you can use an SSH tunnel with a bastion host in the VPC.
-
PrivateLink Starburst Galaxy supports AWS PrivateLink for SQL Server catalogs.
Amazon RDS configuration #
To configure the connection to your database on Amazon RDS you must provide the following details:
- RDS database host: use the fully qualified domain name for the server
available as Endpoint in the Amazon RDS console under Connectivity &
security. Typically
dbidentifier.random.regionname.rds.amazonaws.com. - RDS database port: port of the server available with endpoint. Typically 1433 for SQL Server. The port is configurable for your database in the Amazon RDS console under Connectivity - Database port.
- Database name: used for SQL Server databases to identify
the specific database to connect to.
- RDS database username: specify a username that has the permissions to perform the desired task.
- RDS database password: specify the password for the database username.
The database on Amazon RDS needs to fulfill the following requirements:
- Configured for Public access, available in the Amazon RDS console for your database in Connectivity - Additional configuration
- VPC security group configured to allow Starburst Galaxy access. The specific IP address range/CIDR is dependent on your AWS region, and displayed after a Test connection execution. Add it as an inbound rule to allow the range.
-
Database authentication set to Password authentication.
Azure Database configuration #
The database on Azure Database needs to fulfill the following requirements:
- DB server host: use the fully qualified domain name for the server available as Server name in Essentials, as well as the Connections strings in the Azure Database console.
- DB server port: port of the server available with endpoint. Typically 1433 for SQL Server.
- Database name: used for SQL Server databases to identify the specific database to connect to.
- DB server admin login name: use the Admin username of the Administrator account.
- DB server admin password: use the password for the user.
The database on Cloud SQL needs to fulfill the following requirements from the Connection security section of the Settings for the database:
- A firewall rule configured for the Starburst Galaxy IP address range with Start IP and End IP configured with a random Firewall rule name.
- TLS setting configured for the Minimum TLS version as 1.2
Google Cloud configuration #
Configure the database on Google Cloud SQL by filling in the following required fields:
- Database IP address: use the IP address for the server available as Public IP address in the Cloud SQL console under Connect to this instance.
- Database port: port of the server available with endpoint. Typically 1433 for SQL Server.
- Database name: used for SQL Server databases to identify the specific database to connect to.
- Username: use a configured user with sufficient access.
- Password: use the password for the user.
The database on Google Cloud SQL must fulfill the following requirements:
- Configured for Public IP, available in the Cloud SQL console for your database in Connections - Public IP with an Authorized network configured with the CIDR to allow Starburst Galaxy access. The specific IP address range/CIDR is dependent on your Google Cloud region, and displayed after a Test connection execution.
- Zonal availability set to Single zone.
- User configured with username and password in Users.
Test the connection #
Once you have configured the connection details, click Test connection to confirm data access is working. If the test is successful, you can save the catalog.
If the test fails, look over your entries in the configuration fields, correct any errors, and try again. If the test continues to fail, Galaxy provides diagnostic information that you can use to fix the data source configuration in the cloud provider system.
Connect catalog #
Click Connect catalog, and proceed to set permissions where you can grant access to certain roles.
Set permissions #
This optional step allows you to configure read-only access or full read and write access to the catalog.
Use the following steps to assign read-only access to all roles:
- Select the Read-only catalog switch to grant a set of roles read-only access to the catalog’s schemas, tables, and views.
- Next, use the drop-down menu in the Role-level permissions section to specify the roles that have read-only access.
- Click Save access controls.
You can specify read-only access and read-write access separately for different sets of roles. That is, one set of roles can get full read and write access to all schemas, tables, and views in the catalog, while another set of roles gets read-only access.
Use the following steps to assign read/write access to some or all roles:
- Leave the Read-only catalog switch cleared.
- In the Role-level permissions section:
- Expand the drop-down menu in the Roles with read and write access field and select one or more roles to grant read and write access to.
- Expand the drop-down menu in the Roles with read access field and select one or more roles from the list to grant read-only access to.
- Click Save access controls.

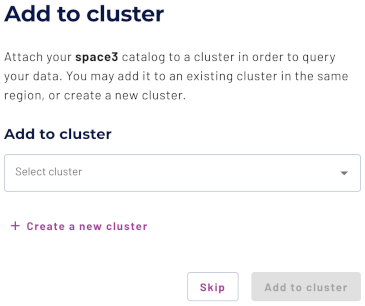
Add to cluster #
You can add your catalog to a cluster later by editing a cluster. Click Skip to proceed to the catalogs page.
Use the following steps to add your catalog to an existing cluster or create a new cluster in the same cloud region:
- In the Add to cluster section, expand the menu in the Select cluster field.
- Select one or more existing clusters from the drop down menu.
- Click Create a new cluster to create a new cluster in the same region, and add it to the cluster selection menu.
-
Click Add to cluster to view your new catalog’s configuration.
SQL support #
The catalog provides read access and write access to data and metadata in SQL Server. It supports the following features:
- Globally available statements
- Read operations
- Write operations
- Data management:
- Schema and table management; see Schema and table management details
Limitations:
CREATE VIEWis not supported.
The following sections provide SQL Server catalog-specific information regarding SQL support.
Data management details #
If a WHERE clause is specified, the DELETE operation only works if the
predicate in the clause can be fully pushed down to the data source.
Schema and table management details #
The catalog does not support renaming tables across multiple schemas. For example, the following statement is supported:
ALTER TABLE catalog.schema_one.table_one RENAME TO catalog.schema_one.table_two
The following statement attempts to rename a table across schemas, and therefore is not supported:
ALTER TABLE catalog.schema_one.table_one RENAME TO catalog.schema_two.table_two
The catalog supports renaming a schema with the ALTER SCHEMA RENAME
statement. ALTER SCHEMA SET AUTHORIZATION is not supported.
Performance #
The catalog includes a number of performance improvements, detailed in the following sections:
Parallelism #
The catalog is able to read data from SQL Server using multiple parallel connections for tables partitioned as described in the SQL Server partitioning documentation.
Use the parallel_connections_count session
property to
enable parallelism in your catalog and to set the number of splits for tables
with a large number of partitions. Setting an integer limits the number of
connections. The default value of 1 disables parallelism.
SET SESSION <galaxy_catalog_name>.parallel_connections_count = 3
Is the information on this page helpful?
Yes
No