File ingestion #
Starburst Galaxy’s file ingestion service lets you continuously ingest data from JSON files in an AWS S3 bucket location into a managed Iceberg table, also known as a live table. Live tables are stored in your AWS S3 bucket.
Live tables can be queried as part of a Starburst Galaxy cluster or by any query engine that can read Iceberg tables.
The Data ingest option is only available to users assigned to roles that have the Manage data ingest account level privilege.
Configure Starburst Galaxy’s file ingest by clicking Data > Data ingest in the navigation menu.
Before you begin #
Galaxy’s file ingest is supported on Amazon Web Services. You must provide:
- An Amazon S3 Standard tier storage location for which you have read and write access.
- An AWS AWS cross-account IAM role to allow access to the S3 bucket.
- An S3 catalog configured to use cross-account IAM role credentials.
- A Galaxy S3 catalog configured to use an AWS Glue metastore or a Starburst Galaxy metastore.
- A Galaxy cluster located in one of the following regions:
- us-east-1
- us-west-2
- eu-central-1
To inquire about support for other regions, contact Starburst Support.
Galaxy ingests compressed or uncompressed newline deliminated JSON (NDJSON) files.
The files are subject to the following constraints:
- Maximum 10GB for a single file
- Maximum 20,000,000 file limit in the source path
To adjust file ingest limits, contact Starburst Support.
Getting started #
To begin file ingestion, create an ingest source and live table.
The following sections walk you through the configuration process:
- Step 1: Connect to a stream source
- Step 2: Land your data in a raw table
- Step 3: Create a transform table and schematize data
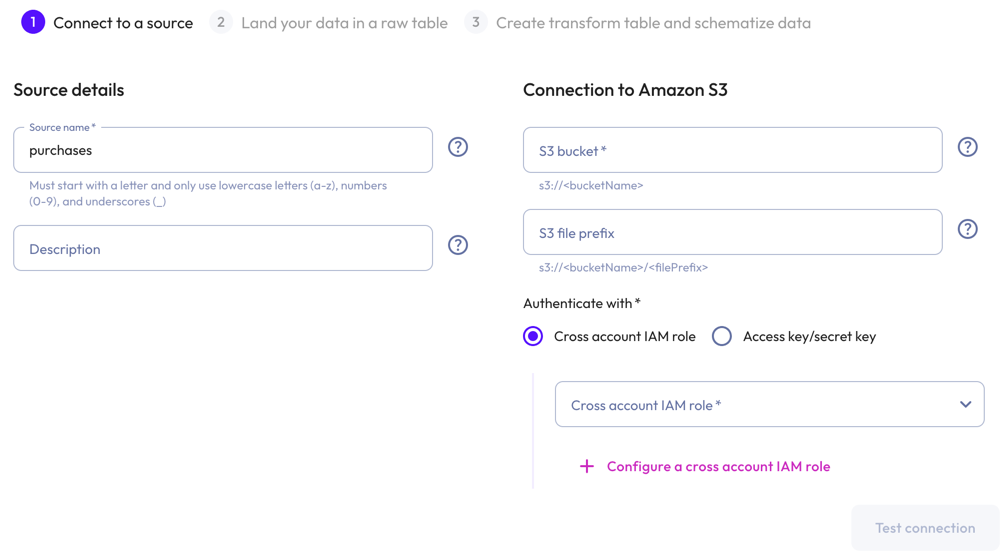
Connect to a source #
From the navigation menu, go to Data > Data ingest.
Click Connect new source, then select the Amazon S3 source.
In the Connect new Amazon S3 dialog:
-
In the Source details section, enter a name for the source and a description.
-
In the Connection to Amazon S3 section, enter the name of the S3 bucket, and the S3 file prefix.
Live tables created using this source specify an exact location under the prefix. If you are creating multiple file ingest live tables, we recommended choosing a prefix which points to the root of all the files you want to ingest.
-
To authenticate with an API key/API secret pairing, enter an API key and an API secret in the respective fields.
-
To authenticate with a cross-account IAM role:
- Select a cross-account role from the drop-down menu.
- To configure a cross-account IAM role, click add
Configure a cross account IAM role.
-
-
Click Test connection to confirm that you have access to the source. If the test fails, check your entries, correct any errors, and try again.
-
If the connection is successful, click Save new source
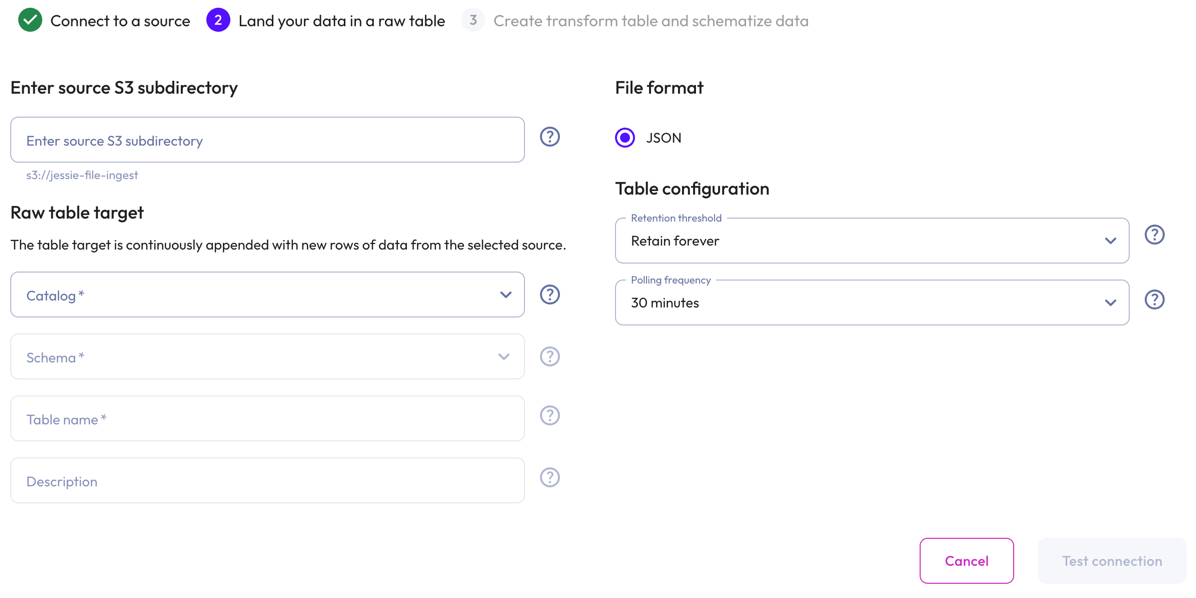
Land your data in a raw table #
-
In the Enter source S3 subdirectory section, you have the option to limit ingestion to a subdirectory with your S3 bucket. To do this, enter the source S3 directory.
-
In the Raw table target section:
- Select a Catalog and Schema from the respective drop-down menus.
- Provide a Table name and Description.
-
In the File format section, the JSON file format is the only available format, and is pre-selected.
-
In the Table configuration section:
-
Set a data Retention threshold: By default, Retain forever is preselected to specify that all data is to be stored in the live table indefinitely. Select a different value to specify how long data is retained before it is automatically purged: 1 day, 7 days, 14 days, 30 days, or 90 days.
-
Set a Polling frequency to detect new files every 30, 60, 90, or 120 minutes.
-
-
Click Test connection to confirm that you have access to the data. If the test fails, check your entries, correct any errors, and try again.
-
If the connection is successful, click Save raw table.
Create a transform table and schematize data #
You can create a transform table at a later time as part of raw table options in live table management. To create a live table now, proceed to create a transform table.
Create a transform table #
-
In the Transform table target section:
- Select a Catalog and Schema from the respective drop-down menus.
- Provide a Table name and Description.
-
In the Table configuration section:
-
Set a data Retention threshold: By default, Retain forever is preselected to specify that all data is to be stored in the live table indefinitely. Select a different value to specify how long data is retained before it is automatically purged: 1 day, 7 days, 14 days, 30 days, or 90 days.
-
Choose an Error handling policy: Continue continues the ingestion process and writes any records that fail to parse to the errors table. Pause and notify stops the ingestion process if any parsing errors occur.
-
-
Click Validate data. If the test fails, check your entries, correct any errors, and try again.
-
Click Next.
Schematize data #
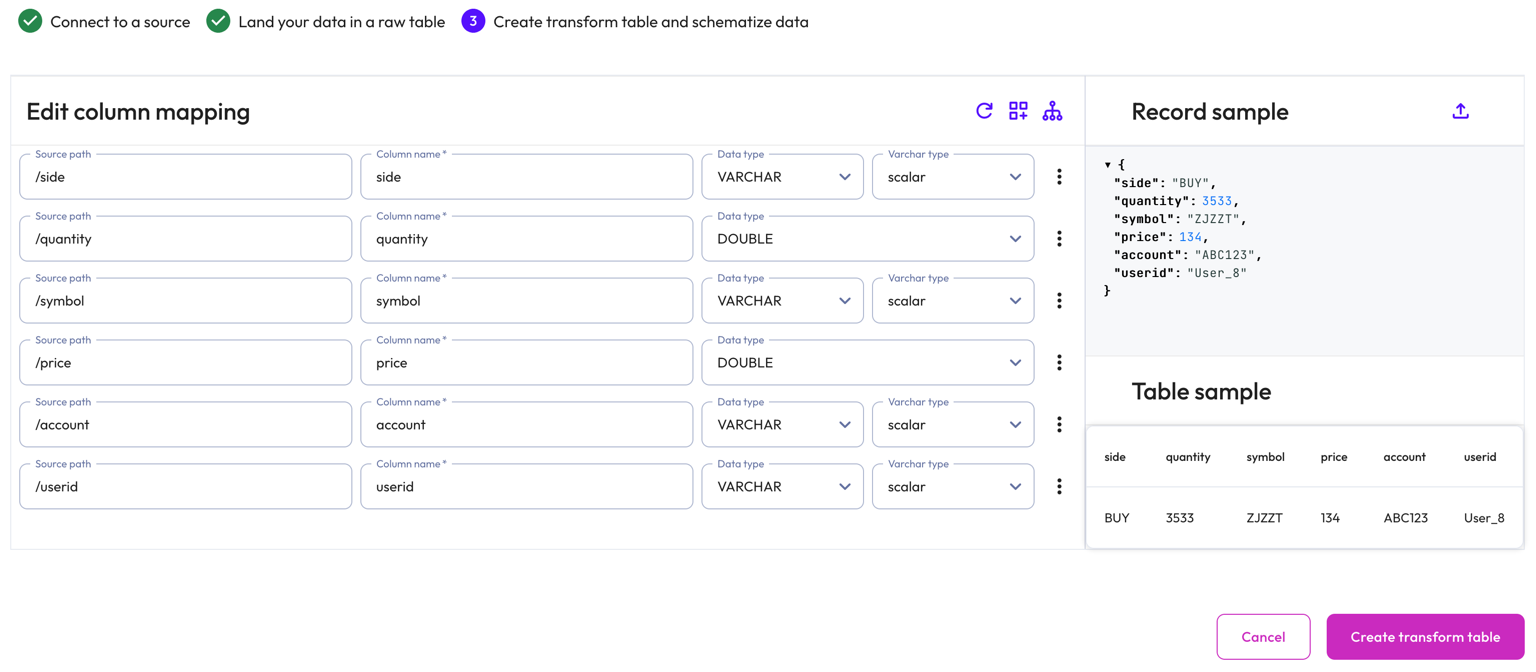
Starburst Galaxy automatically suggests a schema by inferring from the JSON file. Modify the inferred schema by changing field entries and adding and removing columns.
Use the Edit column mapping panel to map the following columns:
- Source path: The location of the record information within the JSON row.
- Column name: Provide a column name for the live table.
- Data type: Specify a data type for the live table column.
- Varchar type: For a
VARCHARtype, specify aSCALARor JSONVARCHARtype. ForTIMESTAMPandTIMESTAMP WITH TIMEZONEtypes, specify aiso601orunixtimetype.
Use themore_vertoptions menu at the end of each row to add or remove columns.
Perform the following actions from the header:
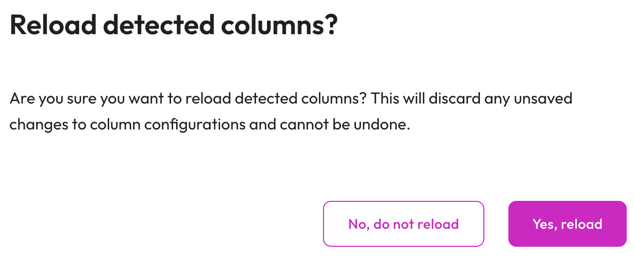
- refresh
Reload detected columns: Restore any altered field entries to the original
inferred values.
- In the Reload detected columns dialog, click Yes, reload to reload detected columns and discard any unsaved changes to column configurations. This action cannot be undone. Otherwise, click No, do not reload.
-
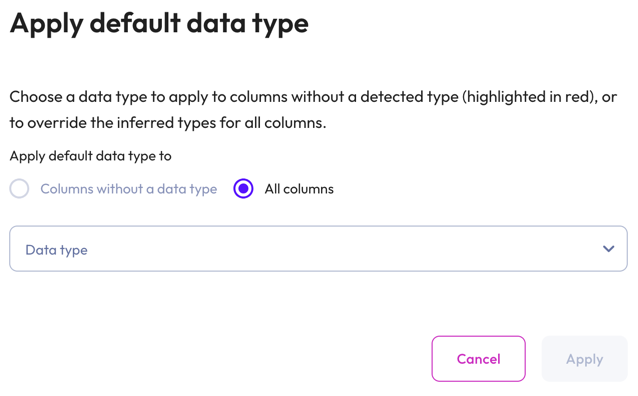
dashboard_customize Set default type: Apply a data type to columns without a detected type or override the inferred types for all columns.
- In the Apply default data type dialog, select Columns without a data type to apply a data type to columns without a detected type (these columns are highlighted in red). Select All columns to override the inferred types for all columns.
- Choose a data type from the data type drop-down menu.
-
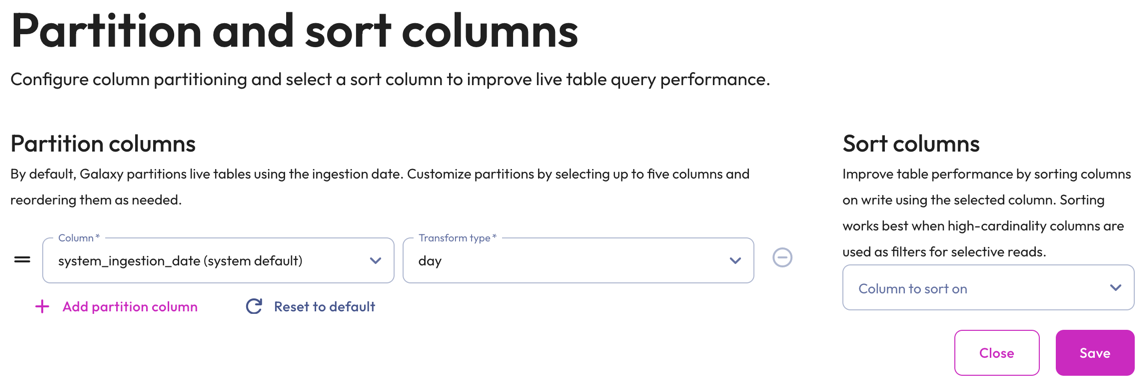
graph_2 Partition and sort columns: Customize partitions and sort columns.
-
In the Partition columns section, select a Column and Transform type from the respective drop-down menus. Transform types change depending on the column. For the bucket transform type, the number of buckets must be between 2 and 512.
Partitioning of
DOUBLEandREALcolumns is not supported. Change the data type to a supported column type.Partition changes are applied to new data immediately, while existing data is updated during the next compaction run.
Partition evolution is not supported.
- In the Sort columns section, choose a column from the drop-down menu.
- To add up to five partition columns, click addAdd partition column.
- To arrange columns, use the drag_handle handle to drag and drop.
- To delete added partitions and reset to the default partitions, click refreshReset to default.
- To remove a column, click do_not_disturb_on.
-
The Record sample panel shows the JSON message sample used to generate the columns. If your Kafka topic is new and does not have any messages for Galaxy to infer, you can manually enter a new JSON sample by clicking upload. Type or paste the new JSON sample in the text area then click Load sample.
The Table sample panel previews the mapped table.
To complete the configuration, click Create transform table.
Data ingest begins in approximately 1-2 minutes. You can run SELECT queries on
the live table like you would on any other table.
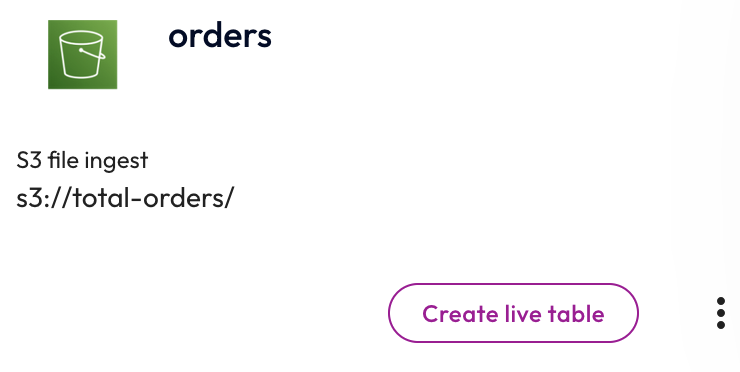
Connected sources #
All connected data sources appear in this section in the order they were created. Create new live table lets you create a new live table.
Delete an ingest source #
To delete an ingest source, you must first decommission all live tables associated with it, then follow these steps:
- In the Connected sources section, locate the data source of interest.
- Click themore_vertoptions menu.
- SelectdeleteDelete ingest source.
-
In the dialog, click Yes, delete.
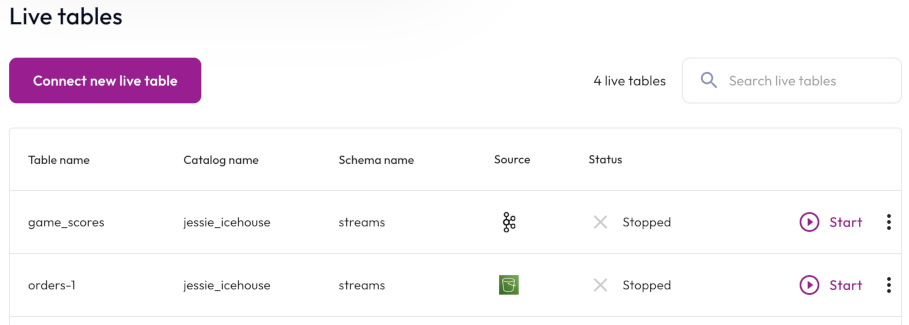
Live table management #
Manage all live table types from the list of live tables, which shows the following columns:
- Table name: The name of the table.
- Status: The status of the live table.
- Catalog: The name of the catalog.
- Schema: The name of the schema.
- Source: The icon representing the data source.
The total number of tables appears next to the search field and also reflects the number of results returned according your search criteria. By default, Starburst Galaxy limits an account to five live tables and 120 MB/s of total throughput. To increase your quota limit, contact Starburst Support.
View All tables or narrow the live tables list to view only Raw tables or Transform tables.
Start and stop ingestion #
Stopping data ingestion for longer than your data retention threshold results in data ingestion starting from the earliest point to include missed messages. To prevent missed messages, resume data ingestion before you hit your retention threshold or choose a longer data retention threshold.
Stop prevents data from being ingested into the live table. Start resumes ingestion from where it left off.
Live table options menus #
The following options menu selections are available for all live tables:
- Edit configurations to change configuration settings.
- Delete live table to decommision.
Additional selections for transform tables include:
- Update schema to make changes to the schema.
- Rewind to savepoint to restore the table to a previous state. See the rewind table to savepoint and backfill instructions in Update schema.
Raw table options #
Here, you can create a transform table at any time. Click Create transform table, and follow the steps in Create a transform table and schematize data.
Transform table options #
You can query a transform table by clicking Query table. This action opens
the query editor with a prepared SELECT statement you can run.
Create a live table #
To create a live table, click Create live table, then choose one of the following options in the Source section:
- To create a new raw table:
- Select Create a new raw table, then choose a source from the drop-down menu.
- Click Next, then follow the steps in Land your data in a raw table.
- To create a new transform table:
- Select Create a new transform table, then choose a raw table from the drop-down menu.
- Follow the steps in Create a transform table and schematize data.
Update schema #
To make changes to the schema, click themore_vertoptions menu, and select Update schema to go to Create a transform table and schematize data.
When you click Save changes, the option to roll back your ingested table to a previous state and backfill data appears in the Backfill Options dialog.
-
In the Backfill Options dialog, choose one of the following:
-
Apply changes without backfill: Previously ingested data remains unchanged and the schema is updated with newly ingested data only.
-
Rewind table to savepoint and backfill: Select a date within the last 30 days and a savepoint from the drop-down menus. The table now appears as it did at the chosen time. Messages that were previously read are reread and rewritten with the updated schema.
The backfill process carries out across the ingestion processes, the output table, and the errors table, ensuring data is not lost or duplicated.
- Click Save.
-
When changing columns, Galaxy automatically performs the Iceberg DDL operations on your live table to alter the schema. Rows present in the table prior to the column changes have NULL values in the newly added columns. Removed columns are no longer accessible to query.
Column changes may take 1-2 minutes to become active.
The following sections detail important management and operational information about live tables.
DDL and DML #
You cannot directly modify the live table definition or delete or update data with SQL statements.
You cannot set a data retention period or purge data from a live table connected to a file ingest data source. To filter out unwanted data, create a view on the live table with a predicate to filter out the data you do not want, or perform the filtering as part of a data pipeline for the data in the source location.
If you still need to perform DML and DDL operations as done on any other Iceberg table, you can decommission the live table.
Live table maintenance #
Learn how Galaxy handles live table maintenance.
Errors table #
Every live table is associated with an errors table that serves as the dead letter table. If Galaxy were to ever encounter an issue while trying to ingest a file, for example, an unrecognized file format, the file exceeds the allowed limit, or a syntax error in a JSON record, an entry is added to the error table corresponding to that file, and the file is skipped.
You can query the errors table the same way you query a live table. The table is
hidden and does not show up when running SHOW TABLES. The table name follows the
convention: "table_name__raw$errors". You must enclose the name in
quotes or the query engine fails to parse the table name.
Decommission a live table #
Decommissioning a live table deletes it from file ingestion and stores it as an unmanaged Iceberg table.
To decommission a live table, follow these steps:
- Locate the table of interest.
- Click themore_vertoptions menu, and select deleteDelete live table.
- In the Delete ingest source dialog, click Yes, delete.
Best practices #
Adhere to the following recommendations to ensure the best results when ingesting file data.
-
Confirm that the source JSON files contain newline delimited records before attempting to create a live table schema mapping or before attempting to ingest file data into a live table.
-
Verify that the data in the source files was successfully ingested into the live table before purging it. If Galaxy has not ingested a file after several polling intervals have transpired, check the errors table for any detected errors.
-
Exceeding the 20,000,000 file limit stops the ingestion process. Ensure that the total number of files in the S3 source path does not exceed the maximum limit by deleting files from the S3 source location after they have been successfully ingested.
Security #
Any modifications made to the data or metadata files may corrupt the Iceberg table. Starburst Galaxy cannot ingest to or manage data in a corrupted table.
Recommended: Apply the principles of least privilege to users who are granted permissions to perform operations on data in the S3 bucket where Iceberg tables are stored.
Recommended: Place Iceberg managed tables in a separate bucket with tighter AWS governance.
Is the information on this page helpful?
Yes
No