Delta Lake table format #
Great Lakes connectivity abstracts the details of using different table formats and file types when using object storage catalogs.
This page describes the features specific to the Delta Lake table format when used with Great Lakes connectivity.
Specify Delta Lake format #
Delta Lake connectivity allows querying data stored in Delta Lake tables, including Databricks Delta Lake. Delta Lake tables are automatically detected and read based on information in the storage environment’s associated metadata.
For an object storage catalog that specifies Delta Lake as its default table
format, no special syntax
is required. A simple CREATE TABLE statement creates a Delta Lake format
table.
There is no format parameter for Delta Lake. To create a Delta Lake table when
the default format is not Delta Lake, add type='delta' as a table property in
your CREATE statement. For example:
CREATE TABLE galaxy_delta.default.my_partitioned_table
WITH (
type = 'delta',
location = 's3://my-bucket/at/this/path',
partitioned_by = ARRAY['regionkey'],
checkpoint_interval = 5
)
AS
SELECT name, comment, regionkey
FROM tpch.tiny.nation;
Table properties #
As part of a CREATE TABLE statement, append further comma-separated table
properties as needed.
| Table property | Description |
|---|---|
partitioned_by |
Specifies table partitioning. If a table is partitioned by
column regionkey, this property is set with
partitioned_by=ARRAY['regionkey']. |
location |
Specifies the file system location URI for the table. |
checkpoint_interval |
Specifies the checkpoint interval in seconds. |
change_data_feed_enabled |
Enables storing change data feed entries. |
column_mapping_mode |
Specifies the column mapping mode. Possible values are ID,
NAME, or NONE.
Defaults to NONE. |
deletion_vectors_enabled |
Enables deletion vectors. Defaults to false. |
in_commit_timestamp_enabled |
Enables storing inCommitTimstamp in every commit.
Defaults to false. |
For example:
CREATE TABLE galaxy_delta.default.my_partitioned_table
WITH (
type = 'delta',
location = 's3://my-bucket/at/this/path',
partitioned_by = ARRAY['regionkey'],
checkpoint_interval = 5
)
AS
SELECT name, comment, regionkey
FROM tpch.tiny.nation;
Delta Lake metadata table #
The $history metadata table provides a log of the metadata changes made to a
Delta Lake table. Query the metadata table by appending $history to a table
name:
SELECT * FROM "galaxy_delta.default.my_partitioned_table$history";
Table procedures #
Use the CALL statement to perform data manipulation or administrative tasks.
Procedures must include a qualified catalog name. For example, for a catalog
named galaxy_delta:
CALL galaxy_delta.system.example_procedure();
The following Delta Lake table procedures are available:
drop_extended_stats #
system.drop_extended_stats('schema_name', 'table_name');
Drops the extended statistics for a specified table in a specified schema.
register_table #
system.register_table('schema_name', 'table_name', 's3://bucket-name/lakehouse/data/table_name_location');
Allows the caller to register an existing Delta Lake table in the metastore, using its existing transaction logs and data files.
unregister_table #
system.unregister_table('schema_name', 'table_name');
Allows the caller to unregister an existing Delta Lake table from the metastore without deleting the data.
vacuum #
system.vacuum('schema_name', 'table_name', 'retention_period');
Specify retention_period with standard SQL time period values such as '7d'.
The vacuum procedure removes all old files that are not in the transaction
log. Additionally, it removes files that are not necessary for read table
snapshots newer than the current time minus the retention period defined by the
retention period parameter.
Users with INSERT and DELETE permissions on a table can run vacuum as
follows:
All parameters are required and must be presented in the following order:
- Schema name
- Table name
- Retention period
Table functions #
Your current active role must have the following privileges:
- Create a table for a schema.
- Execute the
table_changestable function.
In the navigation menu, assign the following privileges:
Create table privileges:
If some of the following steps are not possible after you select the role to change, that role may already have the Create table privilege.
- Click Access control > Roles and privileges.
- Click the name of the role you want to change.
- Click Privileges > Add privilege > Table.
- Click Schema.
- From the drop-down menu, select the catalog of interest.
- In the next section, either select All schemas or from the drop-down menu, select the name of the schema of interest.
- Select Allow.
- In What can they do, select Create table.
- Click Add privilege.

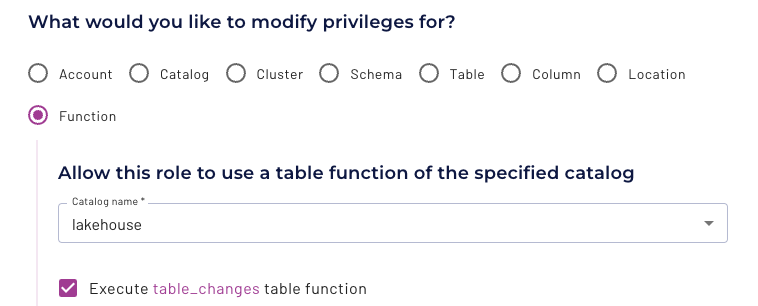
table_changes function privilege:
- Click Access control > Roles and privileges.
- Click the name of the role you want to change.
- Click Privileges > Add privilege > Function.
- From the drop-down menu, select the catalog of interest.
- Select Execute table_changes table function.
- Click Add privilege.
For more details, read about assigning privileges to roles.
table_changes #
The table_changes function allows reading Change Data Feed (CDF) entries to
expose row-level changes between two versions of a Delta Lake table.
When the change_data_feed_enabled table property is set to true on a
specific Delta Lake table, Great Lakes connectivity records change
events for all data changes made on the table after change_data_feed_enabled
was enabled. This includes the row data and metadata, which indicates whether
the specified row was inserted, deleted, or updated.
The following example displays the changes made on the table:
SELECT * FROM TABLE( catalog_name.system.table_changes( 'schema_name','table_name', since_version => 0 ));
The optional since_version value is the version from which changes are shown.
If a value is not provided, the function produces change events starting from
when the table was created. The default value is 0.
In addition to returning the columns present in the table, the
table_changesfunction returns the following values for each change event:
| Name | Description |
|---|---|
_change_type |
Gives the type of change that occurred. Possible values are
insert, delete, update_preimage
, and update_postimage. |
_commit_version |
Shows the table version for which the change occurred. |
_commit_timestamp |
Represents the timestamp for the commit in which the specified change happened. |
The commit versions can also be retrieved from the $history metadata table.
The following SQL statements are examples of using the table_change function:
-- CREATE TABLE with type Delta and Change Data Feed enabled:
CREATE TABLE catalog_name.schema_name.table_name (page_url VARCHAR, domain VARCHAR, views INTEGER)
WITH (type='delta', change_data_feed_enabled = true);
-- INSERT data:
INSERT INTO catalog_name.schema_name.table_name
VALUES ('url1', 'domain1', 1), ('url2', 'domain2', 2), ('url3', 'domain1', 3);
INSERT INTO catalog_name.schema_name.table_name
VALUES ('url4', 'domain1', 400), ('url5', 'domain2', 500), ('url6', 'domain3', 2);
-- UPDATE and modify data:
UPDATE catalog_name.schema_name.table_name SET domain = 'domain4'
WHERE views = 2;
-- SELECT and view table changes:
SELECT * FROM TABLE( system.table_changes('test_schema', 'pages', 1))
ORDER BY _commit_version ASC;
The following output from the previous SQL statements shows what changes happened in which version:
| page_url | domain | views | _commit _type |
_commit _version |
_commit _timestamp |
|---|---|---|---|---|---|
| url4 | domain1 | 400 | insert | 2 | 2023-03-10T21:22:23.000+0000 |
| url5 | domain2 | 500 | insert | 2 | 2023-03-10T21:22:23.000+0000 |
| url6 | domain3 | 2 | insert | 2 | 2023-03-10T21:22:23.000+0000 |
| url2 | domain2 | 2 | update_preimage | 3 | 2023-03-10T22:23:24.000+0000 |
| url2 | domain4 | 2 | update_postimage | 3 | 2023-03-10T22:23:24.000+0000 |
| url6 | domain3 | 2 | update_preimage | 3 | 2023-03-10T22:23:24.000+0000 |
| url6 | domain4 | 2 | update_postimage | 3 | 2023-03-10T22:23:24.000+0000 |
ALTER TABLE EXECUTE #
The ALTER TABLE EXECUTE
statement followed by a command and parameters modifies the table according to
the specified procedure and parameters. For Delta Lake tables, ALTER TABLE
EXECUTE supports the optimize command.
Use the => operator for passing named parameter values. The left side is
the name of the parameter and the right side is the value being passed:
ALTER TABLE galaxy_delta.schema_name.table_name EXECUTE optimize(file_size_threshold => '10MB');
optimize #
The optimize procedure improves read performance by rewriting the content of a
specific table to reduce the number of files. This process increases file size.
If the table is partitioned, the data compaction acts separately on each
partition selected for optimization.
All files with a size below the optional file_size_threshold parameter are
merged. The default value is 100MB.
ALTER TABLE galaxy_delta.schema_name.table_name EXECUTE optimize;
The following statement merges files in a table that are under the 10MB file
size threshold:
ALTER TABLE galaxy_delta.schema_name.table_name EXECUTE optimize(file_size_threshold => '10MB');
Optimize specific partitions using a WHERE clause with the columns used as
partition_key value.
ALTER TABLE galaxy_delta.schema_name.table_name EXECUTE optimize
WHERE partition_key = 1;
Session properties #
See session properties on the Great Lakes connectivity page to understand how these properties are used.
The following table describes the session properties supported by the Delta Lake table format.
| Session property | Description |
|---|---|
checkpoint_filtering_enabled |
Enable pruning of data file entries as well as data file statistics
columns which are irrelevant for the query when reading Delta Lake
checkpoint files. The default value is false. |
compression_codec |
The compression codec is used when writing new data files. The
possible values are:
SNAPPY. |
extended_statistics_enabled |
Enables statistics collection with the ANALYZE
SQL statement and the use of extended statistics. The default value is
true. The statistics_enabled session
property must be set to true. Otherwise, the collection
of any statistics is disabled.Use the ANALYZE
statement to populate data size and number of distinct values (NDV)
extended table statistics in Delta Lake. The minimum value, maximum
value, value count, and null value count statistics are computed on
the fly out of the transaction log of the Delta Lake table. |
extended_statistics_collect_ on_write |
Enable collection of extended statistics for write operations. The
default value is true. The statistics_enabled
session property must be set to true. Otherwise, the
collection of any statistics is disabled. |
legacy_create_table_with_ existing_location_enabled |
Enable using the CREATE
TABLE statement to register an existing table. The default value
is true. |
max_initial_split_size |
Sets the initial data size for a single read section assigned to a
worker. The default value is 32MB. |
max_split_size |
Sets the largest data size for a single read section assigned to a
worker. The default value is 64MB. |
orc_writer_max_dictionary_memory |
The maximum dictionary memory. The default value is
16MB. |
orc_writer_max_stripe_rows |
The maximum stripe row count. The default value is
10000000. |
orc_writer_max_stripe_size |
The maximum stripe size. The default is 64B. |
orc_writer_min_stripe_size |
The minimum stripe size. The default value is 32MB. |
orc_writer_validate_mode |
The level of detail in ORC validation. The possible
values are:
BOTH. |
orc_writer_validate_percentage |
The percentage of written files to validate by rereading them. The
default value is 0. |
parquet_native_zstd_ decompressor_enabled |
Enable using native ZSTD library for faster
decompression of Parquet files. The default value is
true. |
parquet_use_column_index |
Use the Parquet column index. The default value is true.
|
remove_orphan_files_min_ retention |
The minimum retention for the files taken into account for removal by
the remove_orphan procedure. The default value is
7d. |
timestamp_precision |
Specifies the precision for the timestamp columns in Hive tables.
The possible values are:
MILLISECONDS. |
use_file_size_from_metadata |
Use the file size stored in Iceberg metadata. The default value is
true. |
vacuum_min_retention |
The minimum retention threshold for the files taken into account for
removal by the vacuum procedure. The default
value is 7d. |
Delta Lake SQL support #
When using the Delta Lake table format with Great Lakes connectivity, the general SQL support details apply.
ALTER
SCHEMA...RENAME TO syntax.Replacing tables #
The catalog supports replacing a table, in case the table already exists, as an atomic operation. Atomic table replacement creates a new snapshot with the new table definition and keeps the existing table history (see $history metadata table).
To replace a table, use CREATE OR REPLACE TABLE and/or CREATE OR REPLACE
TABLE AS. For more information on creating tables, see CREATE
TABLE and CREATE TABLE
AS. These statements do
not support changing table formats defined by the type table property.
After replacement, the table definition is completely new and separate from the old table.
For example, a table example_table can be replaced by a completely new
definition:
CREATE TABLE example_table (
a BIGINT,
b DATE,
c BIGINT)
WITH (type = 'delta');
Use the CREATE OR REPLACE TABLE AS statement to overwrite the table content:
CREATE OR REPLACE TABLE example_table
WITH (type = 'delta') AS
SELECT * FROM (
VALUES
(1, DATE '2024-01-01', BIGINT '10'),
(2, DATE '2024-01-02', BIGINT '20')
) AS t(a, b, c);
Use the CREATE OR REPLACE TABLE statement to change the table definition:
CREATE OR REPLACE TABLE example_table (
a INT,
b DATE,
c BIGINT,
d VARCHAR)
WITH (type = 'delta');
Is the information on this page helpful?
Yes
No