Trino-based architecture #
This topic teaches you the basic architecture of Trino, Starburst Enterprise, and Starburst Galaxy clusters. It assumes that you are familiar with the material in our concepts topic. After reading this topic, you should have a grasp of the main components of Starburst products.
Introduction #
At their heart, Starburst Enterprise and Starburst Galaxy are massively parallel processing (MPP) compute clusters running the distributed SQL query engine, Trino.
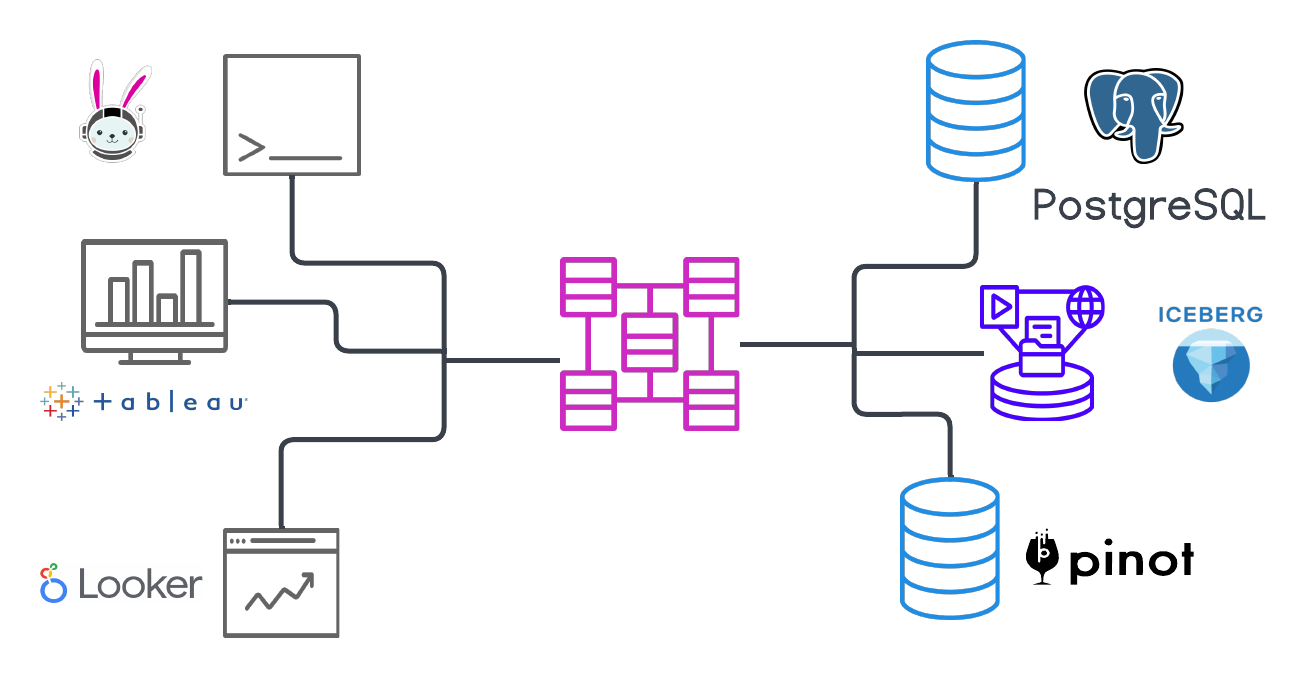
A cluster sits between a user’s favorite SQL client, and the existing data sources that they want to query. Data sources are represented by catalogs, and those catalogs specify the data source connectivity that the cluster needs to query the data sources. With Starburst products, you can query any connected data source.
A Trino cluster has two node types:
- Coordinator - a single server that handles incoming queries, and provides query parsing and analysis, scheduling and planning. Distributes processing to worker nodes.
-
Workers - servers that execute tasks as directed by the coordinator, including retrieving data from the data source and processing data.
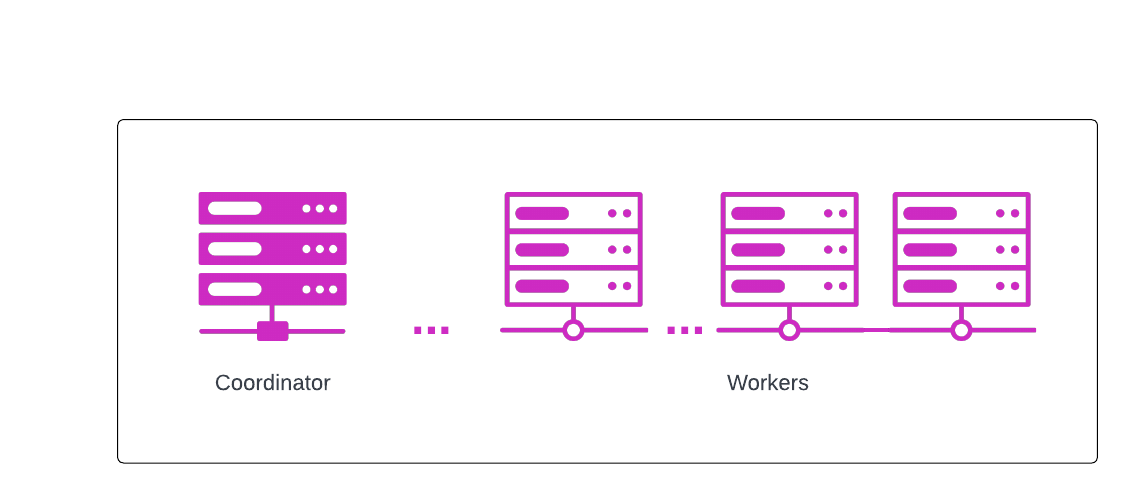
A single server process is run on each node in the cluster; only one node is designated as the coordinator. Worker nodes allow Starburst products to scale horizontally; more worker nodes means more processing resources. You can also scale up by increasing the size of the worker nodes, for example, to m5.8xlarge instances with 32 vCPUs and 128 GiB memory.
Rounding out Trino-based architecture is our suite of connectors. Connectors are what allow Starburst products to separate compute from storage. The configuration necessary to access a data source is called a catalog. Each catalog is configured with the connector for that particular data source. A connector is called when a catalog that is configured to use the connector is used in a query. Data source connections are established based on catalog configuration. The following example shows how this works with PostgreSQL, however, all RDBMS data sources are similarly configured:
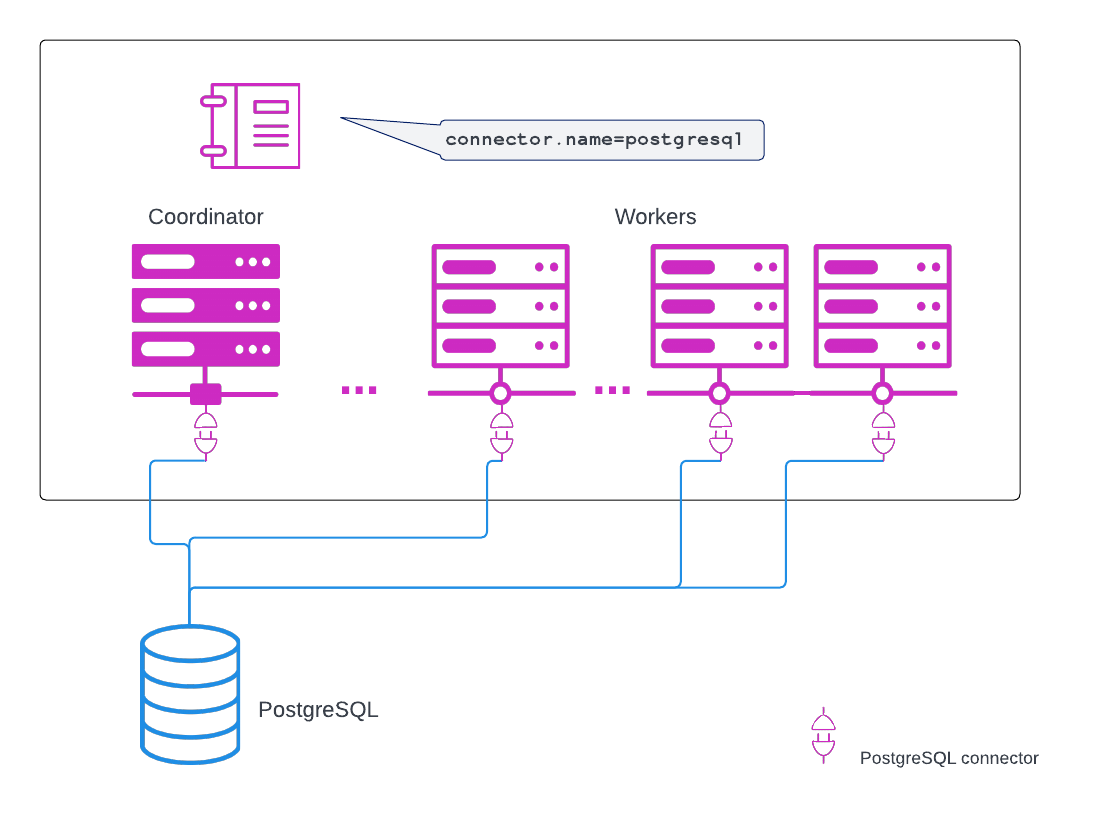
RDBMSs include not only the data, but also the metadata. Metadata is data, such as table definitions and datatypes, that describes tables, schemas, and other data objects. Object stores, however, do not include metadata; their metadata is stored separately, in an RDBMS. The coordinator and workers communicate directly with object storage metastores such as the Hive Metastore and AWS Glue through a catalog’s configured metastore URI:
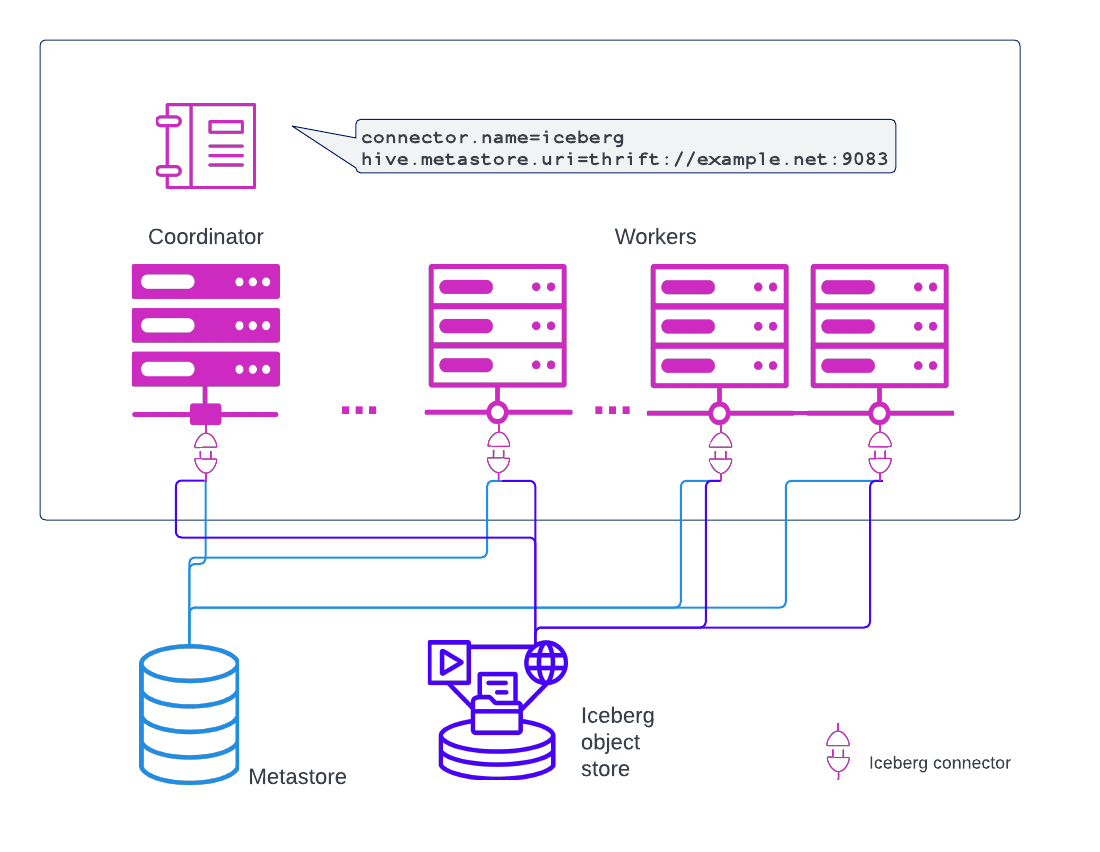
The preceding example shows how this works with an Iceberg data source. Hive and Delta Lake data sources are configured similarly.
Cluster node basics #
There are only two types of nodes in a cluster: a coordinator, and worker nodes. Each node type is responsible for specific activities.
The coordinator #
The coordinator node does several things for each query:
- handles communications with clients
- parses and analyzes queries
- creates a logical model of each query
- plans and optimizes query processing
- schedules query execution
- tracks worker activity
Keep in mind that these activities are per-query, and there can be multiple queries running concurrently that the coordinator must manage. The coordinator is sized differently than are workers. To really understand the coordinator and the resources it needs, let’s learn a bit about its key activities:
Query parsing and analysis
The coordinator receives a SQL statement as plain text. It has to first check the syntax to ensure that it is a valid, well-formed query. Next, it must ensure that the references to objects are valid. In performing these activities, it also determines whether the catalog has sufficient privileges to execute the statement.
Query planning and optimization
The coordinator’s query planner and optimizer work together to create a query
plan that details how to retrieve and process the data. Once the initial query
plan is done, the cost-based optimizer (CBO) helps to create the distributed
query plan. The query plan accounts for things like memory, CPU usage, number of
workers, table statistics, network traffic, and best JOIN ordering. Depending
on the data sources involved, it can also choose optimizations such as predicate
pushdown and partial aggregations.
Communications with clients
The coordinator tracks processing done by the worker nodes and fulfills requests for data from clients. As clients request data, the coordinator requests results from workers and writes the results to an output buffer. The coordinator continues to request data from workers on behalf of clients until all completed results are written to the buffer.
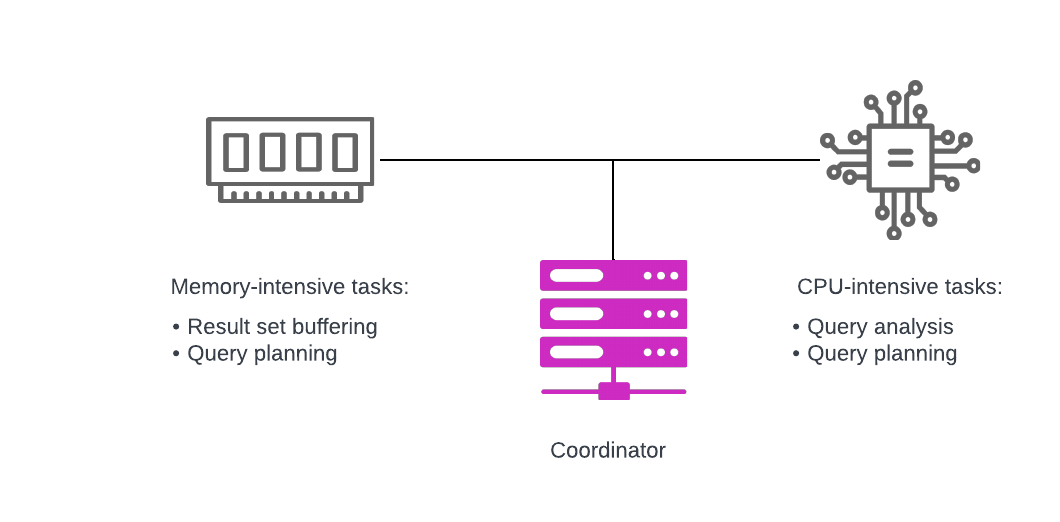
All of these tasks must be done for each concurrent query. It’s important to remember that while the pool of workers can be scaled, the coordinator is always a single node, and it must be sized to handle peak loads.
As you can see, adequate memory and CPUs are key to good performance. Starburst Galaxy makes it easy to configure cluster sizing. SEP can be fine-tuned with separate coordinator and cluster sizing, along with many detailed memory and resource management configuration properties.
Workers #
Worker nodes are responsible for executing tasks assigned to them by the coordinator’s scheduler, including retrieving and processing data from data sources. They communicate not only with the coordinator and data sources, but also with each other directly.
When a cluster executes a query against its cost-optimized query plan, multiple workers retrieve part of the result set at the same time, and then collaborate with each other to process the data until a single worker has the collated, processed data to pass on to the coordinator.
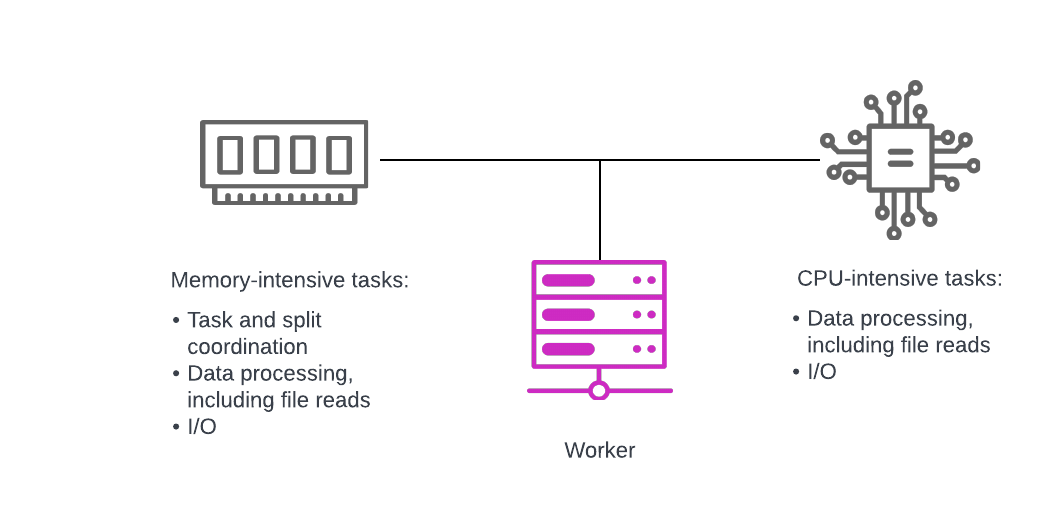
As with the coordinator, worker nodes must handle concurrent queries.
While the number of workers can be scaled, in-flight queries are limited to the resources they started with unless fault-tolerant execution is enabled. Both Starburst Enterprise and Starburst Galaxy provide autoscaling options.
Cluster sizing must be balanced with your scaling strategy to ensure that you can deliver results sets in an acceptable timeframe at peak load.
Communications and security #
Secure communications are available for both Starburst Enterprise and Starburst Galaxy. It is important to have a basic understanding of how things work together in a secure manner, not only within the cluster, but also with clients, data sources, metastores and associated services such as third-party RBAC integrations outside of the cluster.
Data transfer between clients, the coordinator, and workers inside the cluster uses REST-based interactions over HTTP/HTTPS. There are three aspects to cluster communications:
- Client to cluster
- Inside the cluster
- Security between the cluster and data sources
Client to cluster #
Clients communicate only with the coordinator. Secure communication between clients and the cluster is available by configuring TLS. Access to elements of the web UI is controlled through accounts in Starburst Galaxy, and through the built-in access controls in SEP:
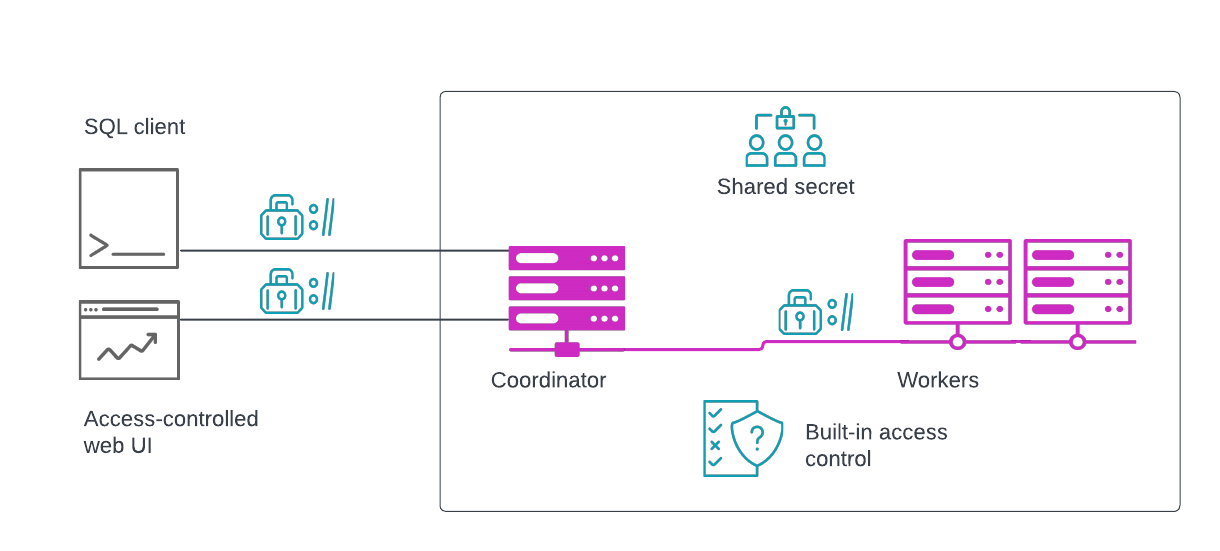
Inside the cluster #
Inside the cluster, workers communicate amongst themselves and with the coordinator. Secure internal communication between nodes is provided through use of a shared secret, TLS, or both in Starburst Enterprise. With Starburst Galaxy, this is taken care of for you.
Security between the cluster and data sources #
Security between the cluster and your data sources is highly dependent upon your organization’s networking and the location of the data sources relative to the cluster.
Both Starburst Galaxy and Starburst Enterprise provide built-in role-based access control for data sources. Starburst Enterprise can, alternatively, integrate with Immuta or Apache Ranger for third-party role-based access control (RBAC) for your data sources.
The built-in access control works alongside supported third-party RBAC systems to provide access control for the web UI:

Is the information on this page helpful?
Yes
No