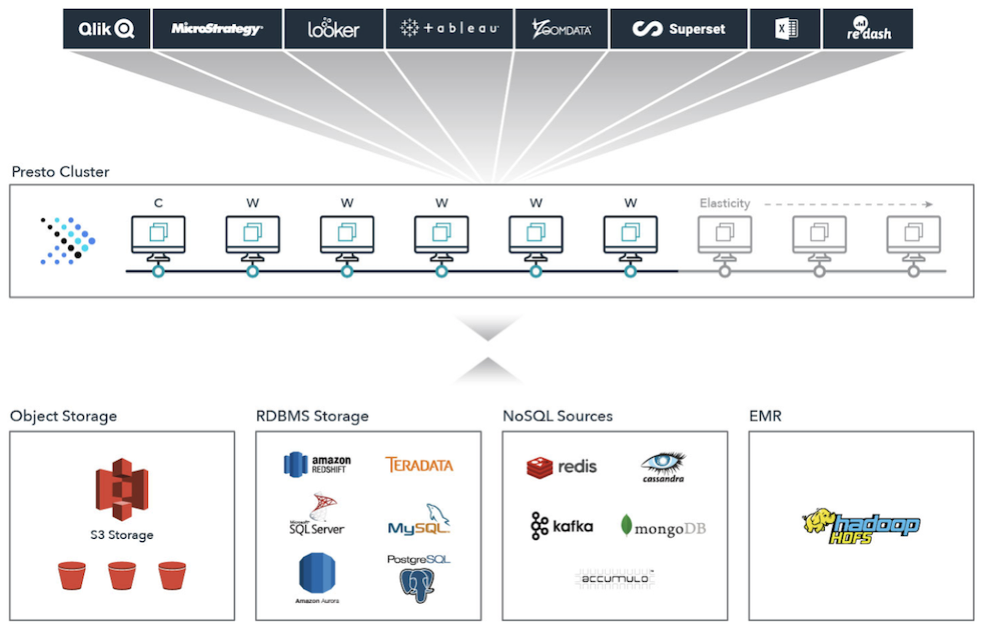
Query data with Starburst #
If you champion data-driven decisions in your org, Starburst has the tools to connect you to the data you need. Starburst brings all your data together in a single, federated environment. No more waiting for data engineering to develop complicated ETL. The data universe is in your hands!
Starburst’s products include Trino’s distributed SQL query engine. Maybe you know a single variant of SQL, or maybe you know a few. Starburst’s SQL is ANSI-compliant and should feel comfortable and familiar. It takes care of translating your queries to the correct SQL syntax for your data source. All you need to access all your data from a myriad of sources is a single JDBC or ODBC client in most cases, depending on your toolkit.
Whether you are a data scientist or analyst delivering critical insights to the business, or a developer building data-driven applications, you’ll find you can easily query across multiple data sources, in a single query. Fast.
How does this work? #
Data platforms in your organization such as Snowflake, Postgres, and Hive are defined by data engineers as catalogs. Catalogs, in turn, define schemas and their tables. Depending on the data access controls in place, discovering what data catalogs are available to you across all of your data platforms can be easy! Even through a CLI, it’s a single, simple query to get you started with your federated data:
trino> SHOW CATALOGS;
Catalog
---------
hive_sales
mysql_crm
(2 rows)After that, you can easily explore schemas in a catalog with the familiar SHOW
SCHEMAS command:
trino> SHOW SCHEMAS FROM hive_sales LIKE `%rder%`;
Schema
---------
order_entries
customer_orders
(2 rows)From there, you can of course see the tables you might want to query:
trino> SHOW TABLES FROM order_entries;
Table
-------
orders
order_items
(2 rows)You might notice that even though you know from experience that some of your
data is in MySQL and others in Hive, they all show up in the unified SHOW
CATALOGS results. From here, you can simply join the data sources from
different platforms as if they were from different tables. You just need to use
their fully qualified names:
trino> SELECT
sfm.account_number
FROM
hive_sales.order_entries.orders oeo
JOIN
mysql_crm.sf_history.customer_master sfm
ON sfm.account_number = oeo.customer_id
WHERE sfm.sf_industry = `medical` AND oeo.order_total > 300
LIMIT 2;How do I get started? #
To begin, get the latest Starburst JDBC or ODBC driver and get it installed. Note that even though you very likely already have a JDBC or ODBC driver installed for your work, you do need the Starburst-specific driver. Be careful not to install either in the same directory with other JDBC or ODBC drivers.
If your data ops group has not already given you the required connection information, reach out to them for the following:
- the JDBC URL -
jdbc:trino://example.net:8080 - whether your org is using SSL to connect
- the type of authentication your org is using - username or LDAP
When you have that info and your driver is installed, you are ready to connect.
What kind of tools can I use? #
More than likely, you can use all your client tools, and even ones on your wishlist with the help of the Clients section of our documentation.
How do I migrate my data sources to Starburst? #
In some cases, this is as easy as changing the sources in your FROM clauses.
For some queries there could be slight differences between your data sources’
native SQL and SQL, so some minor query editing is required. Rather than
changing these production queries on the fly, we suggest using
Starburst’s query editors or the Trino
CLI to test your existing queries before making changes
to production.
If you are migrating from Hive, we have a migration guide in our documentation.
Is the information on this page helpful?
Yes
No