Discover new object storage files #
The Schema discovery pane on the catalog level of the catalog explorer lets you examine the metadata of the specified object storage location. Schema discovery is for catalogs that connect object storage data sources only.
Use schema discovery to identify and register tables or views that are newly added to a known schema location. For example, a logging process might drop a new log file every hour, rolling over from the previous hour’s log file. The purpose of schema discovery is to find the newly added files to make sure Starburst Galaxy knows how to query them.
To use schema discovery successfully, keep the following in mind:
- Schema discovery requires the Allow creating external tables option to be enabled for the metastore when creating the catalog.
- Because each table consists of a single file format, different file formats cannot exist in the same directory. You must create a separate directory for each file format.
- Schema discovery is only available to catalogs that support write operations.
List of discoveries #
For catalogs that have run discovery before, the Schema discovery tab shows a list of previous runs with the following columns:
- Source: The source URL for the bucket used for discovery. Click the source name to open the discovery results pane.
- Timestamp The timestamp when the discovery was run.
- Status: The current status of each discovery instance, such the last successful discovery run, or whether the discovery is in progress.
- Changes: Displays a summary of the changes made during the discovery run, such as the number of tables created.
- Log: Shows visibility
View log. Click this link to open the log events pane for that event. - Rerun: Click cached
Rerunto run schema discovery on the source again. This option performs a diff on the location and returns any changes found.
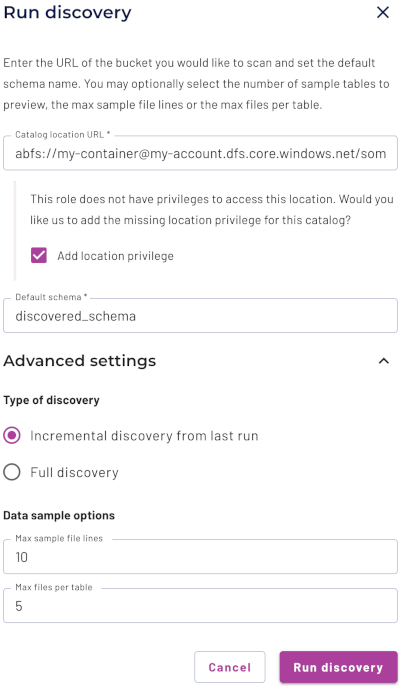
Run schema discovery #
To discover newly added tables, click Run schema discovery. This lets you analyze a specified root object in an object store location and return the structure of any discovered tables.
-
In the Catalog location URL field, select the URL of the bucket and directory to scan from the drop-down menu. You can typically find a schema’s URL as the
locationproperty in the Definition tab of the schema level of the catalog explorer.Note: Schema discovery follows the pattern ofschema/table/<files/partition>. It cannot run on a file. For example,s3://my-s3-bucket/my_csv_file.csvdoes not work.A role in your current active role set must have the location privilege for the specified location. This privilege is automatically added by the discovery process if not already present.
-
Enter the name of a schema in the Set default schema field. This is designated for newly discovered tables that are not part of an existing schema.
-
Optionally open the Advanced settings section.
a. Specify one of the following scan types for this schema discovery run:
- Incremental discovery from last run scans for tables created in the specified schemas since the last schema discovery run. This is the default selection.
- Full discovery runs a full discovery scan on the specified location,
potentially finding tables already registered with Starburst Galaxy.
b. Specify the maximum number of lines to show in sample files, and/or specify the maximum number of files per table.
-
Click Run schema discovery.
Examine discovery results #
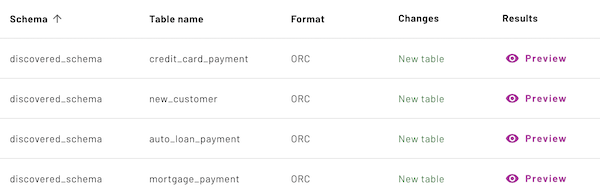
A successful discovery run opens the Select schemas pane, which shows a list of schemas with the following columns:
- Schema: The name of the schema that contains the discovered tables. For a detailed view of changes, expand each entry.
- Tables: The number of tables added to the schema since the last scan.
- Partitions: The number of partitions in the table, if any.
- Path: The URL of the schema and table.
The next step is to register the discovered tables with Galaxy. Select one or more schemas, or select a set of tables within a schema that you would like to register. Then click Create all tables. The table registration process runs for a few moments, then opens the Log events pane to show progress.
Log events #
The log event pane shows a list of log entries for each discovery related event. View a summary of the number of successful query executions and the number of errors that occurred during the discovery run.
The list of log events includes the following information:
- Status: The outcome of the event. A check_circle green checkmark indicates a successful query execution, and a error red exclamation mark indicates an error.
- Timestamp: The timestamp when the event occurred.
- Query text: The SQL query execution text, such as
CREATE TABLE, orCREATE SCHEMA. Click the text to view the full query. - Message: A message detailing the log event, such as the successful creation of a schema, or an error message.
Click Finish to return to the main Schema discovery tab.
Supported formats #
Schema discovery identifies the Iceberg, Delta Lake, and Hive table formats supported by Starburst Galaxy’s Great Lakes connectivity. Schema discovery does not identify Hudi tables.
register_table procedure. For Hive
tables, schema discovery registers tables using the table metadata.Schema discovery identifies tables and views that are saved in the following file formats:
JSONCSVORCPARQUET
Schema discovery identifies tables and views that use the following compression codecs:
ZSTDLZ4SNAPPYGZIPDEFLATEBZIP2LZOLZOP
Schema discovery locates certain file formats as described on the file formats page.
Is the information on this page helpful?
Yes
No