Starburst for data engineers #
Starburst Enterprise platform (SEP) is a fast, interactive distributed SQL query engine that decouples compute from data storage. SEP lets you query data where it lives, including Hive, Snowflake, MySQL or even proprietary data stores. A single SEP query can combine data from all these data sources and more forming a data mesh.
Starburst can greatly reduce reliance expensive, complex and often brittle ETL frameworks and their pipelines. Because it uses data instead of disk to execute queries across the cluster, it’s also fast. SEP can pull your landing times forward, and help you meet or beat your SLAs.
How does this work? #
SEP comes with supported connectors providing high performance SQL-based access to most of the data platforms in your organization - such as Teradata, Oracle, PostgreSQL, and Hive. Each data platform is defined as a catalog. Catalogs, in turn, define schemas and their tables. Catalogs also, at a minimum, define the connector that SEP uses to connect to that data source:
connector.name=sqlserver
connection-url=jdbc:sqlserver://<host>:<port>;database=<database>
connection-user=root
connection-password=secret
Once you have your connection established, many connectors have configuration properties that help you tune the connector’s performance, such as for timeouts, retries and connection limits.
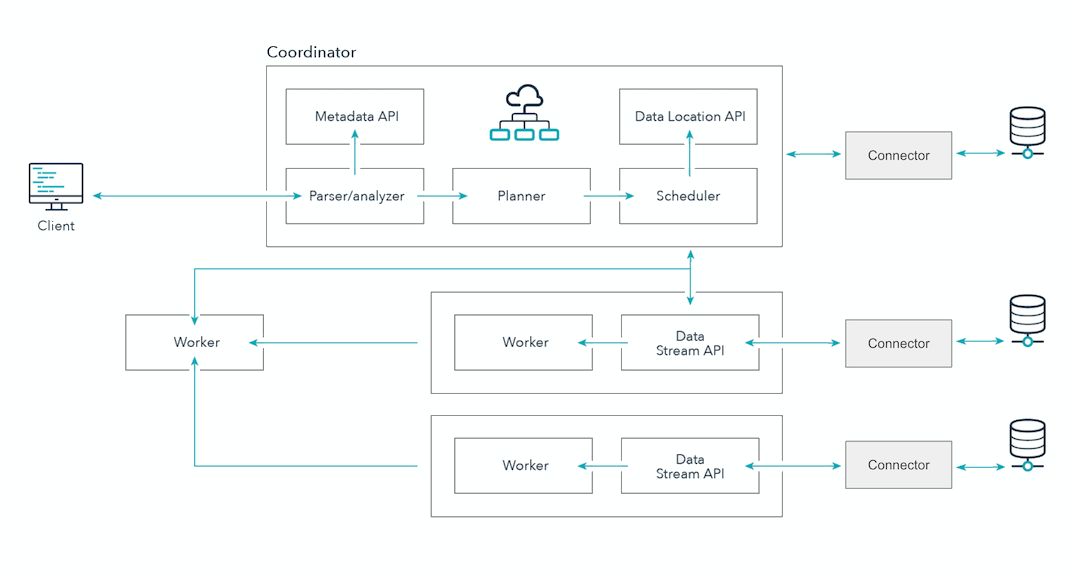
SEP uses an ANSI-compliant SQL that should feel comfortable and familiar. SEP takes care of translating your queries to the correct SQL syntax for your data source. If you are migrating from Hive, we have a migration guide in our documentation.
How do I get started? #
As a first step you should read our guide to choose your Starburst product.
We recommend starting with a trial of Starburst Galaxy, our cloud-native and fully-managed Trino SQL query engine.
Is the information on this page helpful?
Yes
No